
Page 31 - Read Online
P. 31
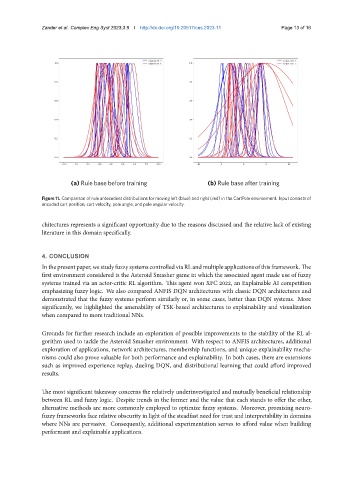
Zander et al. Complex Eng Syst 2023;3:9 I http://dx.doi.org/10.20517/ces.2023.11 Page 13 of 16
(a) Rule base before training (b) Rule base after training
Figure 11. Comparison of rule antecedent distributions for moving left (blue) and right (red) in the CartPole environment. Input consists of
encoded cart position, cart velocity, pole angle, and pole angular velocity.
chitectures represents a significant opportunity due to the reasons discussed and the relative lack of existing
literature in this domain specifically.
4. CONCLUSION
Inthepresentpaper, westudyfuzzysystemscontrolledviaRLandmultipleapplicationsofthisframework. The
first environment considered is the Asteroid Smasher game in which the associated agent made use of fuzzy
systems trained via an actor-critic RL algorithm. This agent won XFC 2022, an Explainable AI competition
emphasizing fuzzy logic. We also compared ANFIS DQN architectures with classic DQN architectures and
demonstrated that the fuzzy systems perform similarly or, in some cases, better than DQN systems. More
significantly, we highlighted the amenability of TSK-based architectures to explainability and visualization
when compared to more traditional NNs.
Grounds for further research include an exploration of possible improvements to the stability of the RL al-
gorithm used to tackle the Asteroid Smasher environment. With respect to ANFIS architectures, additional
exploration of applications, network architectures, membership functions, and unique explainability mecha-
nisms could also prove valuable for both performance and explainability. In both cases, there are extensions
such as improved experience replay, dueling DQN, and distributional learning that could afford improved
results.
The most significant takeaway concerns the relatively underinvestigated and mutually beneficial relationship
between RL and fuzzy logic. Despite trends in the former and the value that each stands to offer the other,
alternative methods are more commonly employed to optimize fuzzy systems. Moreover, promising neuro-
fuzzy frameworks face relative obscurity in light of the steadfast need for trust and interpretability in domains
where NNs are pervasive. Consequently, additional experimentation serves to afford value when building
performant and explainable applications.