
Page 26 - Read Online
P. 26
Page 8 of 16 Zander et al. Complex Eng Syst 2023;3:9 I http://dx.doi.org/10.20517/ces.2023.11
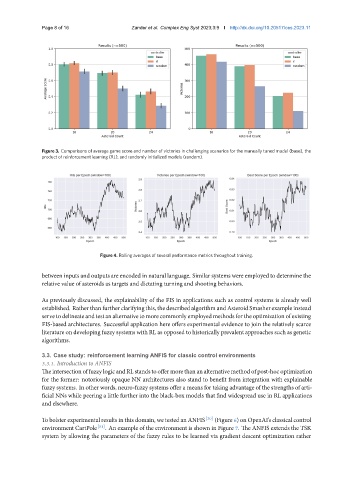
Figure 3. Comparisons of average game score and number of victories in challenging scenarios for the manually tuned model (base), the
product of reinforcement learning (RL), and randomly initialized models (random).
Figure 4. Rolling averages of several performance metrics throughout training.
between inputs and outputs are encoded in natural language. Similar systems were employed to determine the
relative value of asteroids as targets and dictating turning and shooting behaviors.
As previously discussed, the explainability of the FIS in applications such as control systems is already well
established. Ratherthanfurtherclarifyingthis, thedescribed algorithm andAsteroidSmasherexampleinstead
servetodelineateandtestanalternativetomorecommonlyemployedmethods fortheoptimizationofexisting
FIS-based architectures. Successful application here offers experimental evidence to join the relatively scarce
literature on developing fuzzy systems with RL as opposed to historically prevalent approaches such as genetic
algorithms.
3.3. Case study: reinforcement learning ANFIS for classic control environments
3.3.1. Introduction to ANFIS
Theintersectionoffuzzy logic andRLstandstooffermorethananalternativemethod ofpost-hoc optimization
for the former: notoriously opaque NN architectures also stand to benefit from integration with explainable
fuzzy systems. In other words, neuro-fuzzy systems offer a means for taking advantage of the strengths of arti-
ficial NNs while peering a little further into the black-box models that find widespread use in RL applications
and elsewhere.
To bolster experimental results in this domain, we tested an ANFIS [30] (Figure 6) on OpenAI’s classical control
environment CartPole [51] . An example of the environment is shown in Figure 7. The ANFIS extends the TSK
system by allowing the parameters of the fuzzy rules to be learned via gradient descent optimization rather