
Page 55 - Read Online
P. 55
Page 10 of 14 Li et al. J Mater Inf 2024;4:4 I http://dx.doi.org/10.20517/jmi.2023.41
H adsorption
MDAE(eV) MAE(eV)
Error
MARPD(%) R²
LERN CGCNN SchNet MEGNET
DimeNet ComENet AliGNN
A B C
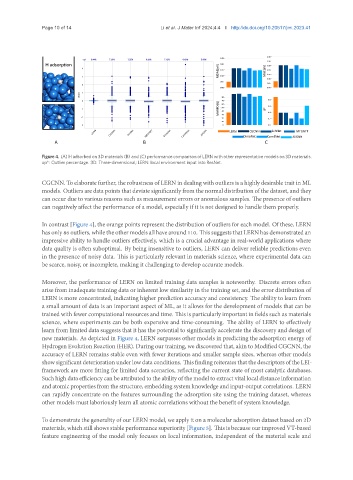
Figure 4. (A) H adsorbed on 3D materials (B) and (C) performance comparison of LERN with other representative models on 3D materials.
op*: Outlier percentage. 3D: Three-dimensional; LERN: local environment input into ResNet.
CGCNN. To elaborate further, the robustness of LERN in dealing with outliers is a highly desirable trait in ML
models. Outliers are data points that deviate significantly from the normal distribution of the dataset, and they
can occur due to various reasons such as measurement errors or anomalous samples. The presence of outliers
can negatively affect the performance of a model, especially if it is not designed to handle them properly.
In contrast [Figure 4], the orange points represent the distribution of outliers for each model. Of these, LERN
has only 86 outliers, while the other models all have around 110. This suggests that LERN has demonstrated an
impressive ability to handle outliers effectively, which is a crucial advantage in real-world applications where
data quality is often suboptimal. By being insensitive to outliers, LERN can deliver reliable predictions even
in the presence of noisy data. This is particularly relevant in materials science, where experimental data can
be scarce, noisy, or incomplete, making it challenging to develop accurate models.
Moreover, the performance of LERN on limited training data samples is noteworthy. Discrete errors often
arise from inadequate training data or inherent low similarity in the training set, and the error distribution of
LERN is more concentrated, indicating higher prediction accuracy and consistency. The ability to learn from
a small amount of data is an important aspect of ML, as it allows for the development of models that can be
trained with fewer computational resources and time. This is particularly important in fields such as materials
science, where experiments can be both expensive and time-consuming. The ability of LERN to effectively
learn from limited data suggests that it has the potential to significantly accelerate the discovery and design of
new materials. As depicted in Figure 4, LERN surpasses other models in predicting the adsorption energy of
Hydrogen Evolution Reaction (HER). During our training, we discovered that, akin to Modified CGCNN, the
accuracy of LERN remains stable even with fewer iterations and smaller sample sizes, whereas other models
show significant deterioration under low data conditions. This finding reiterates that the descriptors of the LEI-
framework are more fitting for limited data scenarios, reflecting the current state of most catalytic databases.
Such high data efficiency can be attributed to the ability of the model to extract vital local distance information
and atomic properties from the structure, embedding system knowledge and input-output correlations. LERN
can rapidly concentrate on the features surrounding the adsorption site using the training dataset, whereas
other models must laboriously learn all atomic correlations without the benefit of system knowledge.
To demonstrate the generality of our LERN model, we apply it on a molecular adsorption dataset based on 2D
materials, which still shows stable performance superiority [Figure 5]. This is because our improved VT-based
feature engineering of the model only focuses on local information, independent of the material scale and