
Page 46 - Read Online
P. 46
Liu et al. Intell Robot 2024;4(4):503-23 I http://dx.doi.org/10.20517/ir.2024.29 Page 515
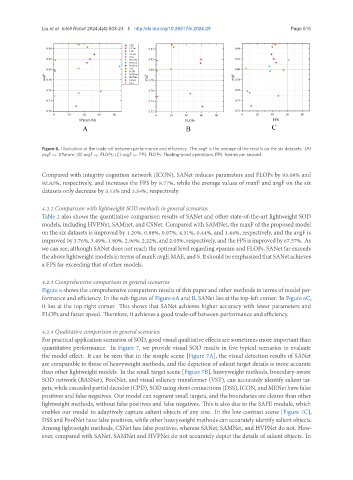
Figure 6. Illustration of the trade-off between performance and efficiency. The avgF is the average of the results on the six datasets. (A)
avgF . #Param; (B) avgF . FLOPs; (C) avgF . FPS. FLOPs: Floating-point operations; FPS: frames per second.
Compared with integrity cognition network (ICON), SANet reduces parameters and FLOPs by 93.08% and
92.82%, respectively, and increases the FPS by 8.77%, while the average values of maxF and avgF on the six
datasets only decrease by 3.13% and 3.54%, respectively.
4.2.2 Comparison with lightweight SOD methods in general scenarios
Table 2 also shows the quantitative comparison results of SANet and other state-of-the-art lightweight SOD
models, including HVPNet, SAMnet, and CSNet. Compared with SAMNet, the maxF of the proposed model
on the six datasets is improved by 1.20%, 0.88%, 0.97%, 4.31%, 0.44%, and 1.44%, respectively, and the avgF is
improvedby3.76%,3.49%,1.80%,2.96%,2.22%,and2.05%,respectively,andtheFPSisimprovedby67.57%. As
we can see, although SANet does not reach the optimal level regarding #param and FLOPs, SANet far exceeds
theabovelightweightmodelsintermsofmaxF,avgF,MAE,andS.ItshouldbeemphasizedthatSANetachieves
a FPS far exceeding that of other models.
4.2.3 Comprehensive comparison in general scenarios
Figure 6 shows the comprehensive comparison results of this paper and other methods in terms of model per-
formance and efficiency. In the sub-figures of Figure 6A and B, SANet lies at the top-left corner. In Figure 6C,
it lies at the top-right corner. This shows that SANet achieves higher accuracy with fewer parameters and
FLOPs and faster speed. Therefore, it achieves a good trade-off between performance and efficiency.
4.2.4 Qualitative comparison in general scenarios
For practical application scenarios of SOD, good visual qualitative effects are sometimes more important than
quantitative performance. In Figure 7, we provide visual SOD results in five typical scenarios to evaluate
the model effect. It can be seen that in the simple scene [Figure 7A], the visual detection results of SANet
are comparable to those of heavyweight methods, and the depiction of salient target details is more accurate
than other lightweight models. In the small target scene [Figure 7B], heavyweight methods, boundary-aware
SOD network (BASNet), PoolNet, and visual saliency transformer (VST), can accurately identify salient tar-
gets, while cascaded partial decoder (CPD), SOD using short connections (DSS), ICON, and MENet have false
positives and false negatives. Our model can segment small targets, and the boundaries are clearer than other
lightweight methods, without false positives and false negatives. This is also due to the SAFE module, which
enables our model to adaptively capture salient objects of any size. In the low-contrast scene [Figure 7C],
DSS and PoolNet have false positives, while other heavyweight methods can accurately identify salient objects.
Among lightweight methods, CSNet has false positives, whereas SANet, SAMNet, and HVPNet do not. How-
ever, compared with SANet, SAMNet and HVPNet do not accurately depict the details of salient objects. In