
Page 38 - Read Online
P. 38
Page 274 Yoseph et al. Art Int Surg 2024;4:267-77 https://dx.doi.org/10.20517/ais.2024.38
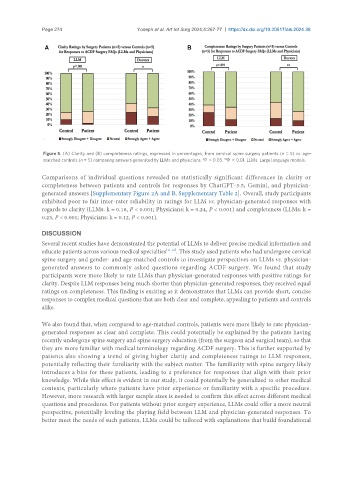
Figure 5. (A) Clarity and (B) completeness ratings, expressed in percentages, from cervical spine surgery patients (n = 5) vs. age-
**
*
matched controls (n = 5) comparing answers generated by LLMs and physicians. P < 0.05. P < 0.01. LLMs: Large language models.
Comparisons of individual questions revealed no statistically significant differences in clarity or
completeness between patients and controls for responses by ChatGPT-3.5, Gemini, and physician-
generated answers [Supplementary Figure 2A and B, Supplementary Table 2]. Overall, study participants
exhibited poor to fair inter-rater reliability in ratings for LLM vs. physician-generated responses with
regards to clarity (LLMs: k = 0.16, P < 0.001; Physicians: k = 0.24, P < 0.001) and completeness (LLMs: k =
0.23, P < 0.001; Physicians: k = 0.12, P < 0.001).
DISCUSSION
Several recent studies have demonstrated the potential of LLMs to deliver precise medical information and
educate patients across various medical specialties [11-13] . This study used patients who had undergone cervical
spine surgery and gender- and age-matched controls to investigate perspectives on LLMs vs. physician-
generated answers to commonly asked questions regarding ACDF surgery. We found that study
participants were more likely to rate LLMs than physician-generated responses with positive ratings for
clarity. Despite LLM responses being much shorter than physician-generated responses, they received equal
ratings on completeness. This finding is exciting as it demonstrates that LLMs can provide short, concise
responses to complex medical questions that are both clear and complete, appealing to patients and controls
alike.
We also found that, when compared to age-matched controls, patients were more likely to rate physician-
generated responses as clear and complete. This could potentially be explained by the patients having
recently undergone spine surgery and spine surgery education (from the surgeon and surgical team), so that
they are more familiar with medical terminology regarding ACDF surgery. This is further supported by
patients also showing a trend of giving higher clarity and completeness ratings to LLM responses,
potentially reflecting their familiarity with the subject matter. The familiarity with spine surgery likely
introduces a bias for these patients, leading to a preference for responses that align with their prior
knowledge. While this effect is evident in our study, it could potentially be generalized to other medical
contexts, particularly where patients have prior experience or familiarity with a specific procedure.
However, more research with larger sample sizes is needed to confirm this effect across different medical
questions and procedures. For patients without prior surgery experience, LLMs could offer a more neutral
perspective, potentially leveling the playing field between LLM and physician-generated responses. To
better meet the needs of such patients, LLMs could be tailored with explanations that build foundational