
Page 35 - Read Online
P. 35
Yoseph et al. Art Int Surg 2024;4:267-77 https://dx.doi.org/10.20517/ais.2024.38 Page 271
Table 3. Inclusion and exclusion criteria used to select cervical spine surgery patients and age-matched controls
Inclusion criteria Exclusion criteria
Speaks and reads English at native level proficiency Participants who did not fill out the study questionnaire
Age > 18 years old Participants who did not consent to participate in the study
Patients must have a history of cervical spine surgery at Stanford from Age-matched controls cannot have a history of spine
2019 to 2023 surgery
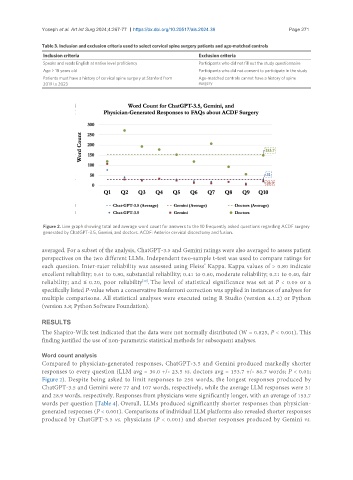
Figure 2. Line graph showing total and average word count for answers to the 10 frequently asked questions regarding ACDF surgery
generated by ChatGPT-3.5, Gemini, and doctors. ACDF: Anterior cervical discectomy and fusion.
averaged. For a subset of the analysis, ChatGPT-3.5 and Gemini ratings were also averaged to assess patient
perspectives on the two different LLMs. Independent two-sample t-test was used to compare ratings for
each question. Inter-rater reliability was assessed using Fleiss’ Kappa. Kappa values of > 0.80 indicate
excellent reliability; 0.61 to 0.80, substantial reliability; 0.41 to 0.60, moderate reliability; 0.21 to 0.40, fair
reliability; and ≤ 0.20, poor reliability . The level of statistical significance was set at P < 0.05 or a
[10]
specifically listed P-value when a conservative Bonferroni correction was applied in instances of analyses for
multiple comparisons. All statistical analyses were executed using R Studio (version 4.1.2) or Python
(version 3.8; Python Software Foundation).
RESULTS
The Shapiro-Wilk test indicated that the data were not normally distributed (W = 0.825, P < 0.001). This
finding justified the use of non-parametric statistical methods for subsequent analyses.
Word count analysis
Compared to physician-generated responses, ChatGPT-3.5 and Gemini produced markedly shorter
responses to every question (LLM avg = 30.0 +/- 23.5 vs. doctors avg = 153.7 +/- 86.7 words; P < 0.01;
Figure 2). Despite being asked to limit responses to 250 words, the longest responses produced by
ChatGPT-3.5 and Gemini were 77 and 107 words, respectively, while the average LLM responses were 31
and 28.9 words, respectively. Responses from physicians were significantly longer, with an average of 153.7
words per question [Table 4]. Overall, LLMs produced significantly shorter responses than physician-
generated responses (P < 0.001). Comparisons of individual LLM platforms also revealed shorter responses
produced by ChatGPT-3.5 vs. physicians (P < 0.001) and shorter responses produced by Gemini vs.