
Page 19 - Read Online
P. 19
Page 103 Liu et al. Art Int Surg 2024;4:92-108 https://dx.doi.org/10.20517/ais.2024.19
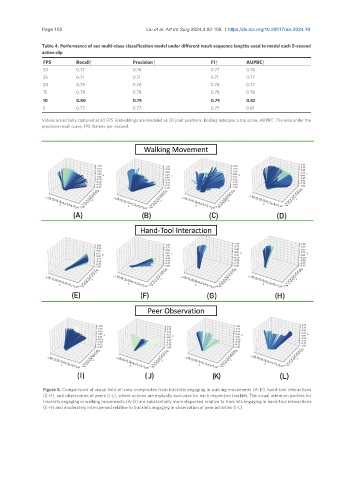
Table 4. Performance of our multi-class classification model under different mesh sequence lengths used to model each 5-second
action clip
FPS Recall↑ Precision↑ F1↑ AUPRC↑
30 0.77 0.76 0.77 0.76
25 0.71 0.71 0.71 0.77
20 0.79 0.76 0.76 0.77
15 0.78 0.78 0.78 0.76
10 0.80 0.79 0.79 0.82
5 0.77 0.77 0.77 0.81
Videos are initially captured at 30 FPS. Embeddings are modeled as 3D joint positions. Bolding indicates a top score. AUPRC: The area under the
precision-recall curve; FPS: frames-per-second.
Figure 5. Comparisons of visual field-of-view composites from tracklets engaging in walking movements (A-D), hand-tool interactions
(E-H), and observation of peers (I-L), where actions are mutually exclusive for each respective tracklet. The visual attention profiles for
tracklets engaging in walking movements (A-D) are substantially more dispersed relative to tracklets engaging in hand-tool interactions
(E-H) and moderately interspersed relative to tracklets engaging in observation of peer activities (I-L).