
Page 16 - Read Online
P. 16
Liu et al. Art Int Surg 2024;4:92-108 https://dx.doi.org/10.20517/ais.2024.19 Page 100
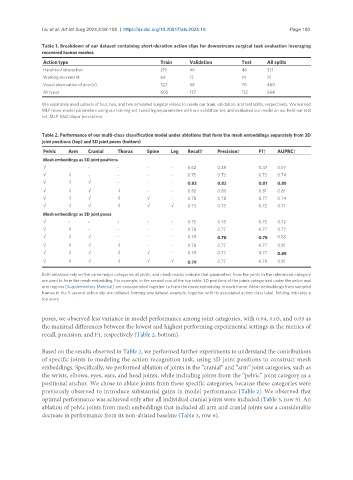
Table 1. Breakdown of our dataset containing short-duration action clips for downstream surgical task evaluation leveraging
recovered human meshes
Action type Train Validation Test All splits
Hand-tool interaction 219 46 48 313
Walking movement 64 13 14 91
Visual observation of peer(s) 322 68 70 460
All types 605 127 132 864
We separately used subsets of four, two, and two simulated surgical videos to create our train, validation, and test splits, respectively. We learned
MLP mixer model parameters using our training set, tuned hyperparameters with our validation set, and evaluated our model on our held-out test
set. MLP: Multi-layer perceptron.
Table 2. Performance of our multi-class classification model under ablations that form the mesh embeddings separately from 3D
joint positions (top) and 3D joint poses (bottom)
Pelvic Arm Cranial Thorax Spine Leg Recall↑ Precision↑ F1↑ AUPRC↑
Mesh embeddings as 3D joint positions
√ - - - - - 0.62 0.38 0.47 0.57
√ √ - - - - 0.75 0.72 0.73 0.74
√ √ √ - - - 0.83 0.82 0.81 0.85
√ √ √ √ - - 0.82 0.80 0.81 0.81
√ √ √ √ √ - 0.78 0.78 0.77 0.74
√ √ √ √ √ √ 0.73 0.73 0.72 0.71
Mesh embeddings as 3D joint poses
√ - - - - - 0.75 0.75 0.75 0.72
√ √ - - - - 0.78 0.77 0.77 0.77
√ √ √ - - - 0.78 0.78 0.78 0.83
√ √ √ √ - - 0.78 0.77 0.77 0.81
√ √ √ √ √ - 0.78 0.77 0.77 0.85
√ √ √ √ √ √ 0.79 0.77 0.78 0.81
Both ablations rely on the same major categories of joints, and check marks indicate that parameters from the joints in the referenced category
are used to form the mesh embedding. For example, in the second row of the top table, 3D positions of the joints categorized under the pelvic and
arm regions [Supplementary Material] are concatenated together to form the mesh embedding in each frame. Mesh embeddings from sampled
frames in the 5-second action clip are collated, forming one dataset example, together with its associated action class label. Bolding indicates a
top score.
poses, we observed less variance in model performance among joint categories, with 0.04, 0.03, and 0.03 as
the maximal differences between the lowest and highest performing experimental settings in the metrics of
recall, precision, and F1, respectively (Table 2, bottom).
Based on the results observed in Table 2, we performed further experiments to understand the contributions
of specific joints to modeling the action recognition task, using 3D joint positions to construct mesh
embeddings. Specifically, we performed ablation of joints in the “cranial” and “arm” joint categories, such as
the wrists, elbows, eyes, ears, and head joints, while including joints from the “pelvic” joint category as a
positional anchor. We chose to ablate joints from these specific categories, because these categories were
previously observed to introduce substantial gains in model performance [Table 2]. We observed that
optimal performance was achieved only after all individual cranial joints were included (Table 3, row 5). An
ablation of pelvic joints from mesh embeddings that included all arm and cranial joints saw a considerable
decrease in performance from its non-ablated baseline (Table 3, row 6).