
Page 49 - Read Online
P. 49
Shapey et al. Art Int Surg 2023;3:1-13 https://dx.doi.org/10.20517/ais.2022.31 Page 7
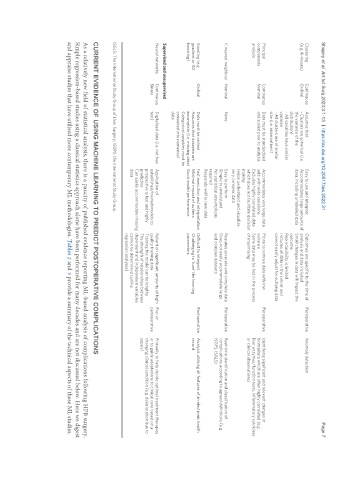
Clustering Continuous Assumes that: Easy to use and interpret Outcomes are specific to the time of Perioperative Anomaly detection
(e.g. K-means) Ordinal - Clusters are spherical (i.e. Accommodates large amounts of analysis and data included
the variance of the data, including unlabelled data Small changes in data will impact the
distribution) outcome
- All variables have similar Reproducibility is limited
variance Includes all data in the cohort and
- All clusters are of similar cannot easily adjust for outlying data
size (i.e. observations)
Principal Continuous Data must be standardised Accommodates very large data Prone to remove data with low Perioperative Identifying significant and relevant changes in
components Nominal and scaled prior to analysis sets with wide variations variance biomarkers which are often highly correlated (e.g.
analysis Excludes highly correlated data Some data may be lost in the process liver enzymes/function tests, inflammatory cytokines
which does not facilitate decision of maximising or clinical observations)
making
Helps understand and visualise
very complex data
K nearest neighbour Nominal None Easy to perform Requires accurate and complete data Perioperative Real-time identification and classification of
Simple to understand Does not easily accommodate large complications according to agreed definitions (e.g.
No statistical assumptions and complex datasets ISGPS, ISGLS)
required
Responds well to new data
Boosting (e.g Ordinal Data must be ordinal Fast execution and interpretation Difficult to interpret Postoperative Analysis utilising all features of an electronic health
gradient or XG Assumes that datasets are Minimal impact of outliers Challenging to ‘tune’ the learning record
boosting) incomplete (i.e. missing data) Good model performance parameters
Categorical variables must be
converted into numerical
data
Supervised and unsupervised
Neural networks Continuous Digitalised data (i.e. not free Application of Reliant on significant amounts of high- Pre- or Primarily to help decide optimal treatment therapies
Binary text) established/trained models to quality training data perioperative or to guide adaptations to clinical care based on a
prospective is fast and highly Training the model can be lengthy changing clinical condition (e.g. deterioration due to
predictive The strength of relationships between sepsis)
Can easily accommodate missing dependent and independent variables
data cannot be determined (unlike
regression analyses)
ISGLS: The International Study Group of Liver Surgery; ISGPS: the International Study Group.
CURRENT EVIDENCE OF USING MACHINE LEARNING TO PREDICT POSTOPERATIVE COMPLICATIONS
As a relatively new field of statistical analysis, there is a paucity of published evidence reporting ML-based analysis of complications following HPB surgery.
Simple regression-based studies using a classical statistics approach alone have been performed for many decades and are not discussed below. Here we digest
and appraise studies that have utilised more contemporary ML methodologies. Tables 2 and 3 provide a summary of the technical aspects of these ML studies.