
Page 45 - Read Online
P. 45
Page 146 Corizzo et al. J Surveill Secur Saf 2020;1:140-50 I http://dx.doi.org/10.20517/jsss.2020.15
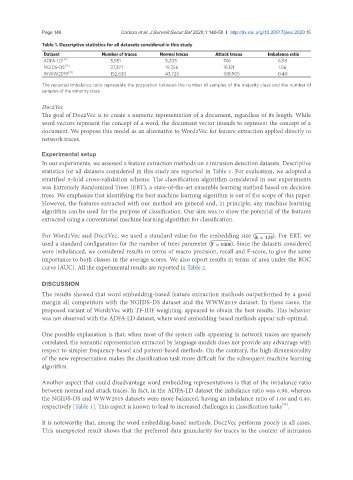
Table 1. Descriptive statistics for all datasets considered in this study
Dataset Number of traces Normal traces Attack traces Imbalance ratio
ADFA-LD [16] 5,951 5,205 746 6.98
NGIDS-DS [17] 37,377 19,256 18,121 1.06
WWW2019 [18] 152,630 43,725 108,905 0.40
The reported imbalance ratio represents the proportion between the number of samples of the majority class and the number of
samples of the minority class
Doc2Vec
The goal of Doc2Vec is to create a numeric representation of a document, regardless of its length. While
word vectors represent the concept of a word, the document vector intends to represent the concept of a
document. We propose this model as an alternative to Word2Vec for feature extraction applied directly to
network traces.
Experimental setup
In our experiments, we assessed 5 feature extraction methods on 3 intrusion detection datasets. Descriptive
statistics for all datasets considered in this study are reported in Table 1. For evaluation, we adopted a
stratified 5-fold cross-validation scheme. The classification algorithm considered in our experiments
was Extremely Randomized Trees (ERT), a state-of-the-art ensemble learning method based on decision
trees. We emphasize that identifying the best machine learning algorithm is out of the scope of this paper.
However, the features extracted with our method are general and, in principle, any machine learning
algorithm can be used for the purpose of classification. Our aim was to show the potential of the features
extracted using a conventional machine learning algorithm for classification.
For Word2Vec and Doc2Vec, we used a standard value for the embedding size ( ). For ERT, we
used a standard configuration for the number of trees parameter ( ). Since the datasets considered
were imbalanced, we considered results in terms of macro precision, recall and F-score, to give the same
importance to both classes in the average scores. We also report results in terms of area under the ROC
curve (AUC). All the experimental results are reported in Table 2.
DISCUSSION
The results showed that word embedding-based feature extraction methods outperformed by a good
margin all competitors with the NGIDS-DS dataset and the WWW2019 dataset. In these cases, the
proposed variant of Word2Vec with TF-IDF weighting, appeared to obtain the best results. This behavior
was not observed with the ADFA-LD dataset, where word embedding-based methods appear sub-optimal.
One possible explanation is that, when most of the system calls appearing in network traces are sparsely
correlated, the semantic representation extracted by language models does not provide any advantage with
respect to simpler frequency-based and pattern-based methods. On the contrary, the high-dimensionality
of the new representation makes the classification task more difficult for the subsequent machine learning
algorithm.
Another aspect that could disadvantage word embedding representations is that of the imbalance ratio
between normal and attack traces. In fact, in the ADFA-LD dataset the imbalance ratio was 6.98, whereas
the NGIDS-DS and WWW2019 datasets were more balanced, having an imbalance ratio of 1.06 and 0.40,
[36]
respectively [Table 1]. This aspect is known to lead to increased challenges in classification tasks .
It is noteworthy that, among the word embedding-based methods, Doc2Vec performs poorly in all cases.
This unexpected result shows that the preferred data granularity for traces in the context of intrusion