
Page 43 - Read Online
P. 43
Page 144 Corizzo et al. J Surveill Secur Saf 2020;1:140-50 I http://dx.doi.org/10.20517/jsss.2020.15
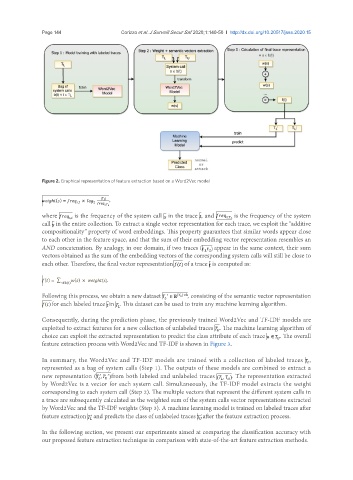
Figure 2. Graphical representation of feature extraction based on a Word2Vec model
,
where is the frequency of the system call in the trace , and is the frequency of the system
call in the entire collection. To extract a single vector representation for each trace, we exploit the “additive
compositionality” property of word embeddings. This property guarantees that similar words appear close
to each other in the feature space, and that the sum of their embedding vector representation resembles an
AND concatenation. By analogy, in our domain, if two traces ( appear in the same context, their sum
vectors obtained as the sum of the embedding vectors of the corresponding system calls will still be close to
each other. Therefore, the final vector representation of a trace is computed as:
.
Following this process, we obtain a new dataset , consisting of the semantic vector representation
for each labeled trace in . This dataset can be used to train any machine learning algorithm.
Consequently, during the prediction phase, the previously trained Word2Vec and TF-IDF models are
exploited to extract features for a new collection of unlabeled traces . The machine learning algorithm of
choice can exploit the extracted representation to predict the class attribute of each trace . The overall
feature extraction process with Word2Vec and TF-IDF is shown in Figure 3.
In summary, the Word2Vec and TF-IDF models are trained with a collection of labeled traces ,
represented as a bag of system calls (Step 1). The outputs of these models are combined to extract a
new representation ( from both labeled and unlabeled traces . The representation extracted
by Word2Vec is a vector for each system call. Simultaneously, the TF-IDF model extracts the weight
corresponding to each system call (Step 2). The multiple vectors that represent the different system calls in
a trace are subsequently calculated as the weighted sum of the system calls vector representations extracted
by Word2Vec and the TF-IDF weights (Step 3). A machine learning model is trained on labeled traces after
feature extraction and predicts the class of unlabeled traces after the feature extraction process.
In the following section, we present our experiments aimed at comparing the classification accuracy with
our proposed feature extraction technique in comparison with state-of-the-art feature extraction methods.