
Page 44 - Read Online
P. 44
Corizzo et al. J Surveill Secur Saf 2020;1:140-50 I http://dx.doi.org/10.20517/jsss.2020.15 Page 145
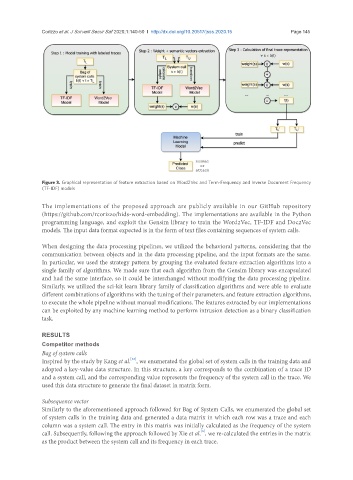
Figure 3. Graphical representation of feature extraction based on Word2Vec and Term-Frequency and Inverse Document Frequency
(TF-IDF) models
The implementations of the proposed approach are publicly available in our GitHub repository
(https://github.com/rcorizzo/hids-word-embedding). The implementations are available in the Python
programming language, and exploit the Gensim library to train the Word2Vec, TF-IDF and Doc2Vec
models. The input data format expected is in the form of text files containing sequences of system calls.
When designing the data processing pipelines, we utilized the behavioral patterns, considering that the
communication between objects and in the data processing pipeline, and the input formats are the same.
In particular, we used the strategy pattern by grouping the evaluated feature extraction algorithms into a
single family of algorithms. We made sure that each algorithm from the Gensim library was encapsulated
and had the same interface, so it could be interchanged without modifying the data processing pipeline.
Similarly, we utilized the sci-kit learn library family of classification algorithms and were able to evaluate
different combinations of algorithms with the tuning of their parameters, and feature extraction algorithms,
to execute the whole pipeline without manual modifications. The features extracted by our implementations
can be exploited by any machine learning method to perform intrusion detection as a binary classification
task.
RESULTS
Competitor methods
Bag of system calls
[22]
Inspired by the study by Kang et al. , we enumerated the global set of system calls in the training data and
adopted a key-value data structure. In this structure, a key corresponds to the combination of a trace ID
and a system call, and the corresponding value represents the frequency of the system call in the trace. We
used this data structure to generate the final dataset in matrix form.
Subsequence vector
Similarly to the aforementioned approach followed for Bag of System Calls, we enumerated the global set
of system calls in the training data and generated a data matrix in which each row was a trace and each
column was a system call. The entry in this matrix was initially calculated as the frequency of the system
[5]
call. Subsequently, following the approach followed by Xie et al. , we re-calculated the entries in the matrix
as the product between the system call and its frequency in each trace.