
Page 96 - Read Online
P. 96
Zhang et al. Intell Robot 2022;2(3):27597
Minitaur
ANYmal
Minitaur
ANYmal
Pybullet
Pybullet
RaiSim
RaiSim
Acceler-
Orienta-
Ve-
Roll
Impulse
and
and
Joint
Base
Slippage
Base
Deviation.
Slip,
Collision,
Joint
Body
Torques,
Base
and
and
Foot
Angles,
Distance,
State,
Target
and
Angular
Self
and
Slippage,
Joint
Gap,
Gap.
Controller:
Clearance,
and
Velocities
Walking
locities,
Action
Power,
Angle.
ations
Speed
tion.
and
Leg Swing Angles and
and
Angles
Joint
Joint
Extensions,
Scales.
Swing
Extensions.
Positions.
Positions.
Desired
Desired
Phase
and
Leg
Locomo-
Con-
Orienta-
(Current&Next),
Height,
Angular
Standing
BaseLinearVelocity, Orientation
State
Positions.
Velocities.
Variables.
Velocity,
Up).
Base
Base
(8-dim),
History.
(Self-Righting).
(Standing
Motor
(2-dim).
and
Command,
Linear
and
Phase
Phase
and
Angles
(2-dim),
and
Angles
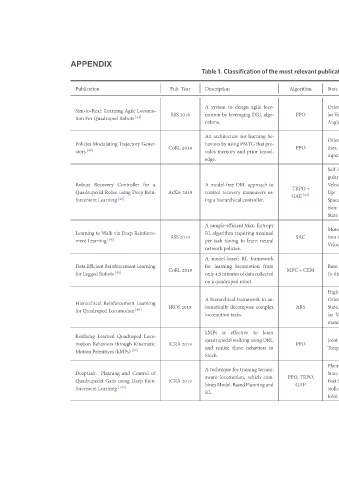
publications research locomotion quadrupedal DRL-based in Robot Simulator Function Reward Space Action Space State Po- Base Previous and Current Angu- Base (2-dim), Orientation Direc- Running Desired sitions, Minitaur Pybullet Pose. Leg Desired lar Velocities (2-dim), and Motor Veloci- and Torques Motor tion, (8-dim). Angles ties. Angles Swing Leg Orientation, Base Angular Veloc- Fre- Extensions, and Minitaur Pybullet Acutual). SpeedGap(Desiredvs. (control Velocity Desired ities, Amplitude, quency, TG. the of Phase and input), Height. Walking An- Base Gravity, Self-Righting: Ve
Space
State,
Base
Velocities
Velocities
(3-dim),
troller:
Motor
Space
Joint
State
tion:
tion
Feet
Up:
relevant Algorithm PPO PPO + TRPO GAE [22] SAC CEM + ARS PPO TRPO, GAE
most MPC PPO,
the loco- algo- be- pro- to us- au- in com-
of agile DRL learning that knowl- approach maneuvers controller. Entropy minimal neural framework from to complex learn to behaviors terrain- which
Classification design leveraging for PMTG using prior and DRL recovery Max. requiring learn to tuning policies. RL locomotion only4.5minutesofdatacollected robot. framework decompose tasks. effective quadrupedal walking using DRL, these training for locomotion, binesModel-BasedPlanningand
1. Description to system by architecture by memory model-free hierarchical a sample-efficient algorithm model-based learning quadruped hierarchical tomatically locomotion is realize technique
Table A motion rithms. An haviors vides edge. A control ing A RL per-task network A for a on A kMPs and Stoch. A aware RL.
Year 2018 2018 2019 2019 2019 2019 2019 2019
Pub. RSS CoRL ArXiv RSS CoRL IROS ICRA ICRA
Locomo- Gener- a for Rein- Reinforce- Learning Loco- Kinematic of Control Rein-
Agile Robots [39] Trajectory Controller Deep using Deep Locomotion [46] Quadruped through (kMPs) [55] and Deep using
Learning Quadruped Modulating Recovery Robot Learning [48] via Walk DataEfficientReinforcementLearning Robots [99] Reinforcement Learned Behaviors Primitives Planning Gaits Learning [100]
APPENDIX Publication Sim-to-Real: For tion Policies ators [49] Robust Quadrupedal forcement to Learning Learning [98] ment Legged for Hierarchical Quadruped for Realizing motion Motion DeepGait: Quadrupedal forcement