
Page 100 - Read Online
P. 100
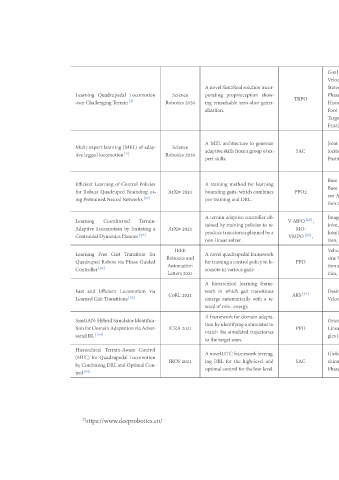
Zhang et al. Intell Robot 2022;2(3):27597
Panther
Jueying-Mini
ANYmal
robot
robot
Black
Mujoco
RaiSim
RaiSim
Velocity,
Base Lin-
Position,
unifor-
Pitch
and
and
Position
Contact.
Velocities,
Velocities,
and
End-Effector Positions,
Desired
Foot
Base
Torque
Gait,
Smoothness,
and
Angular
Positions,
Base
Velocity,
Torque,
Balance,
Quaternion.
Limitations.
uniformity,
Torques,
and
mity,
Joint
Joint
Base
and
ear
Fre-
Cutoff
Joint
Joint
Joint
Leg
Positions.
Positions.
Positions.
Desired
Desired
Desired
Desired
quency,
Lin-
Ac-
VelocityCommand,SineandCo-
sine Values (4 phases), Joint Posi-
tion and Velocity, Angular Veloc-
Posi-
End-Effector,
(Base,
Linear
Previous
and
Joint
Velocity.
Velocities
Base
Velocity
and
Actual
Orientation,
(Base,
Angular
Acceleration,
Command.
Angular
CoM),
Gravity.
and
State
and
Desired
Image,
Joint),
Joint,
Goal Base Gravity, Direction, Joint Frequency, and Velocities Velocity, Angular and Linear FTG Velocities, and States and Frequencies Leg ANYmal-B, and Reward Motion Base Joint Frequencies, and Phases RaiSim Residu- Position Foot ANYmal-C Target Foot Clearance, Collision, Vector, Normal Terrain History, als. Torque. and Smoothness, and Forces Contact Height, Foot States, Contact History, Target Force. External Friction, Velocity, and Height Pose, Base Veloc- (Torque, Regularisation Joint Desired Expert: Ve- Base Gravity, Position, Joint Jueying 3 PyBullet Ref- State,
ities,
Base
tion,
tion
ear
TRPO SAC PPO2 V-MPO [25] , MO- VMPO [26] , PPO ARS [23] PPO SAC
incor- show- gener- generate learning combines ob- re- to framework frame- transitions re- a adapta- trajectories and
solution proprioception zero-shot to for which DRL. controller policies gaits. learning gait with domain high-level
Sim2Real remarkable architecture adaptiveskillsfromagroupofex- method gaits, and adaptive training producetrajectoriesplannedbya solver. quadrupedal for training a control policy to lo- various in hierarchical which automatically energy. min. for tion by identifying a simulator to simulated ones. target AnovelHTCframeworkleverag- the for optimal control for the low-level.
novel porating alization. MEL skills. training bounding pre-training terrain by tained non-linear novel comote in emerge of framework the match the DRL
A ing A pert A A A A work ward A to ing
2020 2020 2021 2021 and 2021 2021 2021 2021
Science Robotics Science Robotics ArXiv ArXiv IEEE Robotics Automation Letters CoRL ICRA IROS
Locomotion adap- of (MEL) Policies Control us- Bounding Networks [57] Terrain- a Imitating Planner [27] for Transition Phase-Guided via Locomotion Control Locomotion
Quadrupedal Terrain [7] Challenging learning locomotion [9] of Learning Quadruped Neural Coordinated by Locomotion Dynamics Gait Free via Robots Efficient Transitions [52] Gait SimGAN: Hybrid Simulator Identifica- tionforDomainAdaptationviaAdver- Terrain-Aware Quadrupedal by Combining DRL and Optimal Con- 3 https://www.deeprobotics.cn/
Learning over Multi-expert legged tive Efficient Robust for Pretrained ing Learning Adaptive Centroidal Learning Quadruped Controller [58] and Fast Learned RL [104] sarial Hierarchical for (HTC) trol [54]