
Page 99 - Read Online
P. 99
Li et al. Intell Robot 2021;1(1):84-98 I http://dx.doi.org/10.20517/ir.2021.06 Page 94
Input
MonoDepth [12]
Zhou et al. [16]
DDVO [23]
GeoNet [18]
Zhan et al. [13]
EPC++(M) [19]
MD2 [22]
Ours
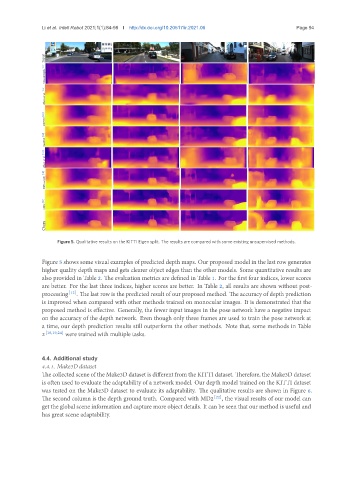
Figure 5. Qualitative results on the KITTI Eigen split. The results are compared with some existing unsupervised methods.
Figure 5 shows some visual examples of predicted depth maps. Our proposed model in the last row generates
higher quality depth maps and gets clearer object edges than the other models. Some quantitative results are
also provided in Table 2. The evaluation metrics are defined in Table 1. For the first four indices, lower scores
are better. For the last three indices, higher scores are better. In Table 2, all results are shown without post-
processing [12] . The last row is the predicted result of our proposed method. The accuracy of depth prediction
is improved when compared with other methods trained on monocular images. It is demonstrated that the
proposed method is effective. Generally, the fewer input images in the pose network have a negative impact
on the accuracy of the depth network. Even though only three frames are used to train the pose network at
a time, our depth prediction results still outperform the other methods. Note that, some methods in Table
2 [18,19,24] were trained with multiple tasks.
4.4. Additional study
4.4.1. Make3D dataset
The collected scene of the Make3D dataset is different from the KITTI dataset. Therefore, the Make3D dataset
is often used to evaluate the adaptability of a network model. Our depth model trained on the KITTI dataset
was tested on the Make3D dataset to evaluate its adaptability. The qualitative results are shown in Figure 6.
The second column is the depth ground truth. Compared with MD2 [22] , the visual results of our model can
get the global scene information and capture more object details. It can be seen that our method is useful and
has great scene adaptability.