
Page 101 - Read Online
P. 101
Li et al. Intell Robot 2021;1(1):84-98 I http://dx.doi.org/10.20517/ir.2021.06 Page 96
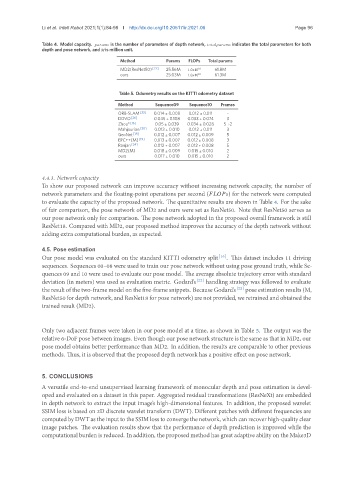
Table 4. Model capacity. is the number of parameters of depth network, indicates the total parameters for both
depth and pose network, and is million unit.
Method Params FLOPs Total params
MD2(ResNet50) [22] 25.56M 1.0 10 10 61.8M
ours 25.03M 1.0 10 10 61.3M
Table 5. Odometry results on the KITTI odometry dataset
Method Sequence09 Sequence10 Frames
ORB-SLAM [33] 0.014 ± 0.008 0.012 ± 0.011 -
DDVO [26] 0.045 ± 0.108 0.033 ± 0.074 3
Zhou* [16] 0.05 ± 0.039 0.034 ± 0.028 5→2
Mahjourian [30] 0.013 ± 0.010 0.012 ± 0.011 3
GeoNet [18] 0.012 ± 0.007 0.012 ± 0.009 5
EPC++(M) [19] 0.013 ± 0.007 0.012 ± 0.008 3
Ranjan [24] 0.012 ± 0.007 0.012 ± 0.008 5
MD2(M) 0.018 ± 0.009 0.015 ± 0.010 2
ours 0.017 ± 0.010 0.015 ± 0.010 2
4.4.3. Network capacity
To show our proposed network can improve accuracy without increasing network capacity, the number of
network parameters and the floating-point operations per second ( ) for the network were computed
to evaluate the capacity of the proposed network. The quantitative results are shown in Table 4. For the sake
of fair comparison, the pose network of MD2 and ours were set as ResNet50. Note that ResNet50 serves as
our pose network only for comparison. The pose network adopted in the proposed overall framework is still
ResNet18. Compared with MD2, our proposed method improves the accuracy of the depth network without
adding extra computational burden, as expected.
4.5. Pose estimation
Our pose model was evaluated on the standard KITTI odometry split [16] . This dataset includes 11 driving
sequences. Sequences 00–08 were used to train our pose network without using pose ground truth, while Se-
quences 09 and 10 were used to evaluate our pose model. The average absolute trajectory error with standard
deviation (in meters) was used as evaluation metric. Godard’s [22] handling strategy was followed to evaluate
the result of the two-frame model on the five-frame snippets. Because Godard’s [22] pose estimation results (M,
ResNet50 for depth network, and ResNet18 for pose network) are not provided, we retrained and obtained the
trained result (MD2).
Only two adjacent frames were taken in our pose model at a time, as shown in Table 5. The output was the
relative 6-DoF pose between images. Even though our pose network structure is the same as that in MD2, our
pose model obtains better performance than MD2. In addition, the results are comparable to other previous
methods. Thus, it is observed that the proposed depth network has a positive effect on pose network.
5. CONCLUSIONS
A versatile end-to-end unsupervised learning framework of monocular depth and pose estimation is devel-
oped and evaluated on a dataset in this paper. Aggregated residual transformations (ResNeXt) are embedded
in depth network to extract the input image’s high-dimensional features. In addition, the proposed wavelet
SSIM loss is based on 2D discrete wavelet transform (DWT). Different patches with different frequencies are
computed by DWT as the input to the SSIM loss to converge the network, which can recover high-quality clear
image patches. The evaluation results show that the performance of depth prediction is improved while the
computational burden is reduced. In addition, the proposed method has great adaptive ability on the Make3D