
Page 100 - Read Online
P. 100
Page 95 Li et al. Intell Robot 2021;1(1):84-98 I http://dx.doi.org/10.20517/ir.2021.06
Table 2. The quantitative results. This table shows the results of our method and other existing methods on KITTI Eigen split [16] . The
best results in every category are in bold. M denotes the training dataset is monocular. * represents the newer results from GitHub
Lower is better Higher is better
Method Train AbsRel SqRel RMSE logRMSE < 1.25 < 1.25 2 < 1.25 3
Zhou* [16] M 0.183 1.595 6.709 0.270 0.734 0.902 0.959
Yang [29] M 0.182 1.481 6.501 0.267 0.725 0.906 0.963
Mahjourian [30] M 0.163 1.240 6.220 0.250 0.762 0.916 0.968
GeoNet* [18] M 0.149 1.060 5.567 0.226 0.796 0.935 0.975
DDVO [23] M 0.151 1.257 5.583 0.228 0.810 0.936 0.974
DF-Net [31] M 0.150 1.124 5.507 0.223 0.806 0.933 0.973
LEGO [32] M 0.162 1.352 6.276 0.252 - - -
Ranjan [24] M 0.148 1.149 5.464 0.226 0.815 0.935 0.973
EPC++ [19] M 0.141 1.029 5.350 0.216 0.816 0.941 0.976
Struct2depth [17] M 0.141 1.026 5.291 0.215 0.816 0.945 0.979
MD2 [22] M 0.131 1.023 5.064 0.206 0.849 0.951 0.979
Ours M 0.125 0.992 5.076 0.203 0.858 0.953 0.979
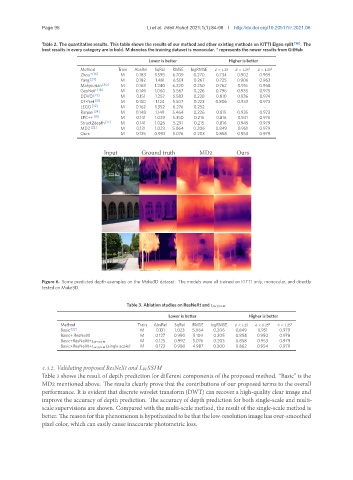
Input Ground truth MD2 Ours
Figure 6. Some predicted depth examples on the Make3D dataset. The models were all trained on KITTI only, monocular, and directly
tested on Make3D.
Table 3. Ablation studies on ResNeXt and
Lower is better Higher is better
Method Train AbsRel SqRel RMSE logRMSE < 1.25 < 1.25 2 < 1.25 3
Basic [22] M 0.131 1.023 5.064 0.206 0.849 0.951 0.979
Basic+ ResNeXt M 0.127 0.990 5.109 0.205 0.854 0.950 0.978
Basic+ResNeXt+ M 0.125 0.992 5.076 0.203 0.858 0.953 0.979
Basic+ResNeXt+ (single scale) M 0.123 0.980 4.987 0.200 0.862 0.954 0.979
4.4.2. Validating proposed ResNeXt and
Table 3 shows the result of depth prediction for different components of the proposed method. “Basic” is the
MD2 mentioned above. The results clearly prove that the contributions of our proposed terms to the overall
performance. It is evident that discrete wavelet transform (DWT) can recover a high-quality clear image and
improve the accuracy of depth prediction. The accuracy of depth prediction for both single-scale and multi-
scale supervisions are shown. Compared with the multi-scale method, the result of the single-scale method is
better. Thereasonforthisphenomenonishypothesizedtobethatthelow-resolutionimagehasover-smoothed
pixel color, which can easily cause inaccurate photometric loss.