
Page 101 - Read Online
P. 101
Shi et al. Art Int Surg 2024;4:247-57 https://dx.doi.org/10.20517/ais.2024.17 Page 255
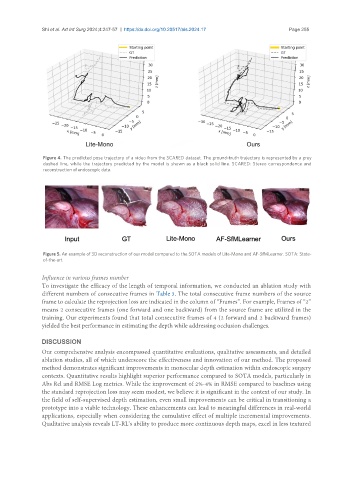
Figure 4. The predicted pose trajectory of a video from the SCARED dataset. The ground-truth trajectory is represented by a grey
dashed line, while the trajectory predicted by the model is shown as a black solid line. SCARED: Stereo correspondence and
reconstruction of endoscopic data.
Figure 5. An example of 3D reconstruction of our model compared to the SOTA models of Lite-Mono and AF-SfMLearner. SOTA: State-
of-the-art.
Influence in various frames number
To investigate the efficacy of the length of temporal information, we conducted an ablation study with
different numbers of consecutive frames in Table 3. The total consecutive frame numbers of the source
frame to calculate the reprojection loss are indicated in the column of “Frames”. For example, Frames of “2”
means 2 consecutive frames (one forward and one backward) from the source frame are utilized in the
training. Our experiments found that total consecutive frames of 4 (2 forward and 2 backward frames)
yielded the best performance in estimating the depth while addressing occlusion challenges.
DISCUSSION
Our comprehensive analysis encompassed quantitative evaluations, qualitative assessments, and detailed
ablation studies, all of which underscore the effectiveness and innovation of our method. The proposed
method demonstrates significant improvements in monocular depth estimation within endoscopic surgery
contexts. Quantitative results highlight superior performance compared to SOTA models, particularly in
Abs Rel and RMSE Log metrics. While the improvement of 2%-4% in RMSE compared to baselines using
the standard reprojection loss may seem modest, we believe it is significant in the context of our study. In
the field of self-supervised depth estimation, even small improvements can be critical in transitioning a
prototype into a viable technology. These enhancements can lead to meaningful differences in real-world
applications, especially when considering the cumulative effect of multiple incremental improvements.
Qualitative analysis reveals LT-RL’s ability to produce more continuous depth maps, excel in less textured