
Page 92 - Read Online
P. 92
Glaser et al. Art Int Surg. 2025;5:1-15 https://dx.doi.org/10.20517/ais.2024.36 Page 9
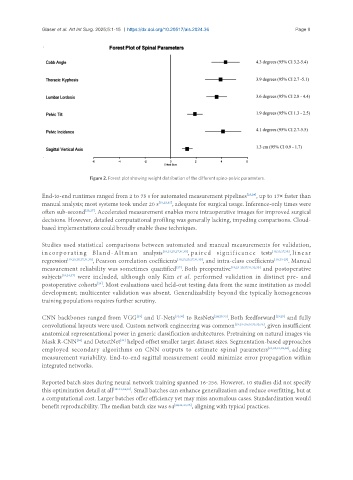
Figure 2. Forest plot showing weight distribution of the different spino-pelvic parameters.
End-to-end runtimes ranged from 2 to 75 s for automated measurement pipelines [23,24] , up to 17× faster than
manual analysis; most systems took under 20 s [19,23,35] , adequate for surgical usage. Inference-only times were
often sub-second [23,27] . Accelerated measurement enables more intraoperative images for improved surgical
decisions. However, detailed computational profiling was generally lacking, impeding comparisons. Cloud-
based implementations could broadly enable these techniques.
Studies used statistical comparisons between automated and manual measurements for validation,
p
l
i n c o r p o r a t i n g B l a n d - A l t m a n analysis [19,23,25,27,31,35] , a i r e d s i g n i f i c a n c e tests [19,23,27,35] , i n e a r
regression [19,23,25,27,31,35] , Pearson correlation coefficients [19,23,25,27,31,35] , and intra-class coefficients [19,23-25] . Manual
measurement reliability was sometimes quantified . Both preoperative [19,23-25,27,31,32,35] and postoperative
[27]
subjects [19,24,37] were included, although only Kim et al. performed validation in distinct pre- and
postoperative cohorts . Most evaluations used held-out testing data from the same institution as model
[24]
development; multicenter validation was absent. Generalizability beyond the typically homogeneous
training populations requires further scrutiny.
CNN backbones ranged from VGG and U-Nets [31,36] to ResNets [24,25,33] . Both feedforward [19,25] and fully
[19]
convolutional layouts were used. Custom network engineering was common [19,23-25,27,31,32,35] , given insufficient
anatomical representational power in generic classification architectures. Pretraining on natural images via
Mask R-CNN and DetectNet helped offset smaller target dataset sizes. Segmentation-based approaches
[36]
[34]
employed secondary algorithms on CNN outputs to estimate spinal parameters [24,25,31,35,36] , adding
measurement variability. End-to-end sagittal measurement could minimize error propagation within
integrated networks.
Reported batch sizes during neural network training spanned 16-256. However, 10 studies did not specify
this optimization detail at all [18-31,34,36] . Small batches can enhance generalization and reduce overfitting, but at
a computational cost. Larger batches offer efficiency yet may miss anomalous cases. Standardization would
benefit reproducibility. The median batch size was 64 [24,31,33,36] , aligning with typical practices.