
Page 77 - Read Online
P. 77
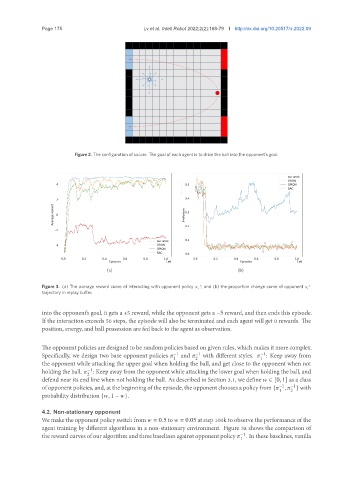
Page 175 Lv et al. Intell Robot 2022;2(2):16879 I http://dx.doi.org/10.20517/ir.2022.09
Figure 2. The configuration of soccer. The goal of each agent is to drive the ball into the opponent’s goal.
(a) (b)
−1
Figure 3. (a) The average reward curve of interacting with opponent policy ; and (b) the proportion change curve of opponent −1
1 1
trajectory in replay buffer.
into the opponent’s goal, it gets a +5 reward, while the opponent gets a −5 reward, and then ends this episode.
If the interaction exceeds 50 steps, the episode will also be terminated and each agent will get 0 rewards. The
position, energy, and ball possession are fed back to the agent as observation.
The opponent policies are designed to be random policies based on given rules, which makes it more complex.
Specifically, we design two base opponent policies and with different styles. : Keep away from
−1
−1
−1
1
1
2
the opponent while attacking the upper goal when holding the ball, and get close to the opponent when not
holding the ball. : Keep away from the opponent while attacking the lower goal when holding the ball, and
−1
2
defend near its end line when not holding the ball. As described in Section 3.1, we define ∈ [0, 1] as a class
of opponent policies, and, at the beginning of the episode, the opponent chooses a policy from { , } with
−1
−1
2
1
probability distribution { , 1 − }.
4.2. Nonstationary opponent
We make the opponent policy switch from = 0.5 to = 0.05 at step 100k to observe the performance of the
agent training by different algorithms in a non-stationary environment. Figure 3a shows the comparison of
the reward curves of our algorithm and three baselines against opponent policy . In these baselines, vanilla
−1
1