
Page 65 - Read Online
P. 65
Boin et al. Intell Robot 2022;2(2):14567 I http://dx.doi.org/10.20517/ir.2022.11 Page 163
(a) No-FRL: 3 Vehicles (b) No-FRL: 4 Vehicles (c) No-FRL: 5 Vehicles
(d) Intra-FRLWA: 3 Vehicles (e) Intra-FRLWA: 4 Vehicles (f) Intra-FRLWA: 5 Vehicles
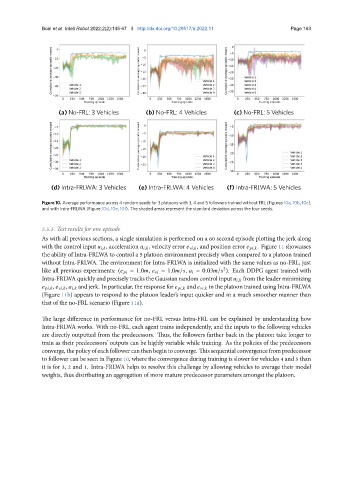
Figure 10. Average performance across 4 random seeds for 3 platoons with 3, 4 and 5 followers trained without FRL (Figures 10a, 10b, 10c),
and with Intra-FRLWA (Figure 10d, 10e, 10f). The shaded areas represent the standard deviation across the four seeds.
3.5.3. Test results for one episode
As with all previous sections, a single simulation is performed on a 60 second episode plotting the jerk along
with the control input , , acceleration , , velocity error , , and position error , . Figure 11 showcases
the ability of Intra-FRLWA to control a 5 platoon environment precisely when compared to a platoon trained
without Intra-FRLWA. The environment for Intra-FRLWA is initialized with the same values as no-FRL, just
like all previous experiments: ( = 1.0 , = 1.0 / , = 0.03 / ). Each DDPG agent trained with
2
Intra-FRLWA quickly and precisely tracks the Gaussian random control input , from the leader minimizing
, , , , , and jerk. In particular, theresponse for , and , in theplatoon trained using Intra-FRLWA
(Figure 11b) appears to respond to the platoon leader’s input quicker and in a much smoother manner than
that of the no-FRL scenario (Figure 11a).
The large difference in performance for no-FRL versus Intra-FRL can be explained by understanding how
Intra-FRLWA works. With no-FRL, each agent trains independently, and the inputs to the following vehicles
are directly outputted from the predecessors. Thus, the followers farther back in the platoon take longer to
train as their predecessors’ outputs can be highly variable while training. As the policies of the predecessors
converge,thepolicyofeachfollowercanthenbegintoconverge. Thissequentialconvergencefrompredecessor
to follower can be seen in Figure 10, where the convergence during training is slower for vehicles 4 and 5 than
it is for 3, 2 and 1. Intra-FRLWA helps to resolve this challenge by allowing vehicles to average their model
weights, thus distributing an aggregation of more mature predecessor parameters amongst the platoon.