
Page 62 - Read Online
P. 62
Page 160 Boin et al. Intell Robot 2022;2(2):14567 I http://dx.doi.org/10.20517/ir.2022.11
Table 5. Performance after training across 4 random seeds. Each simulation result contains 600 time steps
Training method Seed 1 Seed 2 Seed 3 Seed 4 Average system reward Standard deviation
No-FRL -3.84 -3.40 -3.29 -3.21 -3.44 0.24
Intra-FRLGA -2.85 -8.05 -4.23 -2.99 -4.53 2.10
Intra-FRLWA -2.56 -2.60 -2.68 -2.75 -2.65 0.07
(a) No-FRL (b) Intra-FRLGA (c) Intra-FRLWA
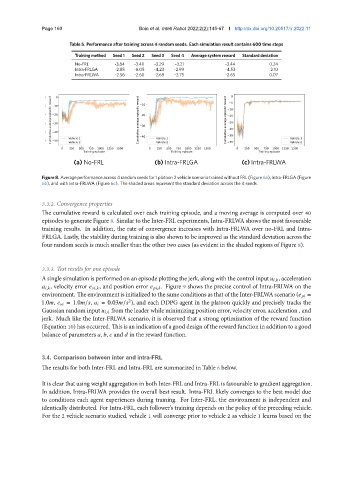
Figure 8. Average performance across 4 random seeds for 1 platoon 2 vehicle scenario trained without FRL (Figure 6a), Intra-FRLGA (Figure
6b), and with Intra-FRLWA (Figure 6c). The shaded areas represent the standard deviation across the 4 seeds.
3.3.2. Convergence properties
The cumulative reward is calculated over each training episode, and a moving average is computed over 40
episodes to generate Figure 8. Similar to the Inter-FRL experiments, Intra-FRLWA shows the most favourable
training results. In addition, the rate of convergence increases with Intra-FRLWA over no-FRL and Intra-
FRLGA. Lastly, the stability during training is also shown to be improved as the standard deviation across the
four random seeds is much smaller than the other two cases (as evident in the shaded regions of Figure 8).
3.3.3. Test results for one episode
A single simulation is performed on an episode plotting the jerk, along with the control input , , acceleration
, , velocity error , , and position error , . Figure 9 shows the precise control of Intra-FRLWA on the
environment. The environment is initialized to the same conditions as that of the Inter-FRLWA scenario ( =
2
1.0 , = 1.0 / , = 0.03 / ), and each DDPG agent in the platoon quickly and precisely tracks the
Gaussian random input , from the leader while minimizing position error, velocity error, acceleration , and
jerk. Much like the Inter-FRLWA scenario, it is observed that a strong optimization of the reward function
(Equation 10) has occurred. This is an indication of a good design of the reward function in addition to a good
balance of parameters , , and in the reward function.
3.4. Comparison between inter and intraFRL
The results for both Inter-FRL and Intra-FRL are summarized in Table 6 below.
It is clear that using weight aggregation in both Inter-FRL and Intra-FRL is favourable to gradient aggregation.
In addition, Intra-FRLWA provides the overall best result. Intra-FRL likely converges to the best model due
to conditions each agent experiences during training. For Inter-FRL, the environment is independent and
identically distributed. For Intra-FRL, each follower’s training depends on the policy of the preceding vehicle.
For the 2 vehicle scenario studied, vehicle 1 will converge prior to vehicle 2 as vehicle 1 learns based on the