
Page 60 - Read Online
P. 60
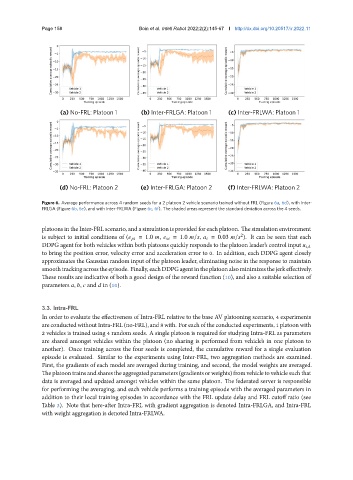
Page 158 Boin et al. Intell Robot 2022;2(2):14567 I http://dx.doi.org/10.20517/ir.2022.11
(a) No-FRL: Platoon 1 (b) Inter-FRLGA: Platoon 1 (c) Inter-FRLWA: Platoon 1
(d) No-FRL: Platoon 2 (e) Inter-FRLGA: Platoon 2 (f) Inter-FRLWA: Platoon 2
Figure 6. Average performance across 4 random seeds for a 2 platoon 2 vehicle scenario trained without FRL (Figure 6a, 6d), with Inter-
FRLGA (Figure 6b, 6e), and with Inter-FRLWA (Figure 6c, 6f). The shaded areas represent the standard deviation across the 4 seeds.
platoons in the Inter-FRL scenario, and a simulation is provided for each platoon. The simulation environment
is subject to initial conditions of ( = 1.0 , = 1.0 / , = 0.03 / ). It can be seen that each
2
DDPG agent for both vehicles within both platoons quickly responds to the platoon leader’s control input ,
to bring the position error, velocity error and acceleration error to 0. In addition, each DDPG agent closely
approximates the Gaussian random input of the platoon leader, eliminating noise in the response to maintain
smoothtrackingacrosstheepisode. Finally,eachDDPGagentintheplatoonalsominimizesthejerkeffectively.
These results are indicative of both a good design of the reward function (10), and also a suitable selection of
parameters , , and in (10).
3.3. IntraFRL
In order to evaluate the effectiveness of Intra-FRL relative to the base AV platooning scenario, 4 experiments
areconductedwithoutIntra-FRL(no-FRL),and8with. Foreachoftheconductedexperiments, 1platoonwith
2 vehicles is trained using 4 random seeds. A single platoon is required for studying Intra-FRL as parameters
are shared amongst vehicles within the platoon (no sharing is performed from vehicle’s in one platoon to
another). Once training across the four seeds is completed, the cumulative reward for a single evaluation
episode is evaluated. Similar to the experiments using Inter-FRL, two aggregation methods are examined.
First, the gradients of each model are averaged during training, and second, the model weights are averaged.
Theplatoontrainsandsharestheaggregatedparameters(gradientsorweights)fromvehicletovehiclesuchthat
data is averaged and updated amongst vehicles within the same platoon. The federated server is responsible
for performing the averaging, and each vehicle performs a training episode with the averaged parameters in
addition to their local training episodes in accordance with the FRL update delay and FRL cutoff ratio (see
Table 3). Note that here-after Intra-FRL with gradient aggregation is denoted Intra-FRLGA, and Intra-FRL
with weight aggregation is denoted Intra-FRLWA.