
Page 21 - Read Online
P. 21
Wu et al. Intell Robot 2022;2(2):10529 I http://dx.doi.org/10.20517/ir.2021.20 Page 119
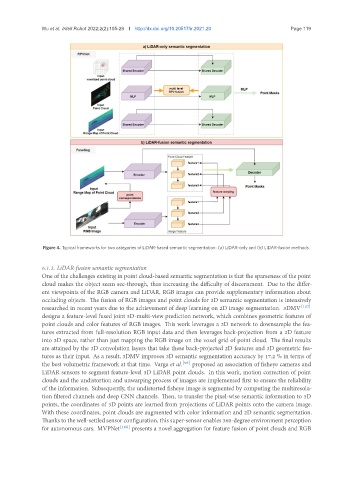
Figure 4. Typical frameworks for two categories of LiDAR-based semantic segmentation: (a) LiDAR-only and (b) LiDAR-fusion methods.
6.1.2. LiDAR-fusion semantic segmentation
One of the challenges existing in point cloud-based semantic segmentation is that the sparseness of the point
cloud makes the object seem see-through, thus increasing the difficulty of discernment. Due to the differ-
ent viewpoints of the RGB camera and LiDAR, RGB images can provide supplementary information about
occluding objects. The fusion of RGB images and point clouds for 3D semantic segmentation is intensively
researched in recent years due to the achievement of deep learning on 2D image segmentation. 3DMV [107]
designs a feature-level fused joint 3D-multi-view prediction network, which combines geometric features of
point clouds and color features of RGB images. This work leverages a 2D network to downsample the fea-
tures extracted from full-resolution RGB input data and then leverages back-projection from a 2D feature
into 3D space, rather than just mapping the RGB image on the voxel grid of point cloud. The final results
are attained by the 3D convolution layers that take these back-projected 2D features and 3D geometric fea-
tures as their input. As a result, 3DMV improves 3D semantic segmentation accuracy by 17.2 % in terms of
the best volumetric framework at that time. Varga et al. [95] proposed an association of fisheye cameras and
LiDAR sensors to segment feature-level 3D LiDAR point clouds. In this work, motion correction of point
clouds and the undistortion and unwarping process of images are implemented first to ensure the reliability
of the information. Subsequently, the undistorted fisheye image is segmented by computing the multiresolu-
tion filtered channels and deep CNN channels. Then, to transfer the pixel-wise semantic information to 3D
points, the coordinates of 3D points are learned from projections of LiDAR points onto the camera image.
With these coordinates, point clouds are augmented with color information and 2D semantic segmentation.
Thanks to the well-settled sensor configuration, this super-sensor enables 360-degree environment perception
for autonomous cars. MVPNet [108] presents a novel aggregation for feature fusion of point clouds and RGB