
Page 70 - Read Online
P. 70
Page 64 Harib et al. Intell Robot 2022;2(1):37-71 https://dx.doi.org/10.20517/ir.2021.19
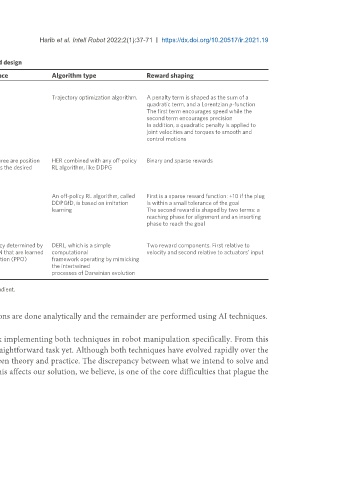
Table 6. DRL for robotic manipulation categorized by state and action space, algorithm and reward design
State space Action space Algorithm type Reward shaping
Levine et al. [176] (2015)
Joint angles and velocities Joint torque Trajectory optimization algorithm. A penalty term is shaped as the sum of a
quadratic term, and a Lorentzian ρ-function
The first term encourages speed while the
second term encourages precision
In addition, a quadratic penalty is applied to
joint velocities and torques to smooth and
control motions
Andrychowicz et al. [180] (2017)
Joint angles 4D action space. The first three are position HER combined with any off-policy Binary and sparse rewards
& velocities + Objects’ positions, rotations & velocities related, the last one specifies the desired RL algorithm, like DDPG
distance
Vecerik et al. [178] (2018)
Joint position and velocity, joint torque, and global pose of the socket and Joint velocities An off-policy RL algorithm, called First is a sparse reward function: +10 if the plug
plug DDPGfD, is based on imitation is within a small tolerance of the goal
learning The second reward is shaped by two terms: a
reaching phase for alignment and an inserting
phase to reach the goal
Gupta et al. [181] (2021)
Depends on the agent morphology and include joint angles, angular Chosen via a stochastic policy determined by DERL, which is a simple Two reward components. First relative to
velocities, readings of a velocimeter, accelerometer, and a gyroscope the parameters of a deep NN that are learned computational velocity and second relative to actuators’ input
positioned at the head, and touch sensors attached to the limbs and head via proximal policy optimization (PPO) framework operating by mimicking
the intertwined
processes of Darwinian evolution
DRL: Deep reinforcement learning; HER: Hindsight Experience Replay; DDPG: Deep Deterministic Policy Gradient.
techniques, or to merge the analytical and AI approaches such that some functions are done analytically and the remainder are performed using AI techniques.
We then briefly presented RL and DRL before we surveyed the previous work implementing both techniques in robot manipulation specifically. From this
overview, it was clear that RL and DRL for robotics are not ready to offer a straightforward task yet. Although both techniques have evolved rapidly over the
past few years with a wide range of applications, there is still a huge gap between theory and practice. The discrepancy between what we intend to solve and
what we solve in practice, and accurately explaining the differences and how this affects our solution, we believe, is one of the core difficulties that plague the
RL/DRL research community.