
Page 61 - Read Online
P. 61
Zhuang et al. Intell Robot 2024;4(3):276-92 I http://dx.doi.org/10.20517/ir.2024.18 Page 282
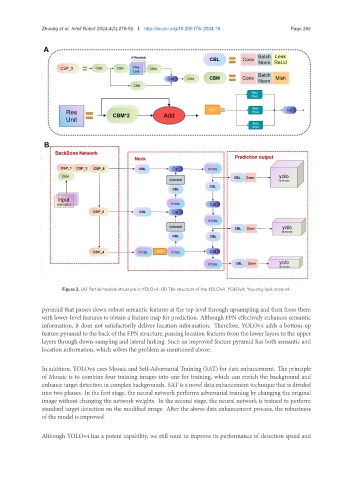
Figure 3. (A) Partial module structure in YOLOv4; (B) The structure of the YOLOv4. YOLOv4: You only look once v4.
pyramid that passes down robust semantic features at the top level through upsampling and then fuses them
with lower-level features to obtain a feature map for prediction. Although FPN effectively enhances semantic
information, it does not satisfactorily deliver location information. Therefore, YOLOv4 adds a bottom-up
feature pyramid to the back of the FPN structure, passing location features from the lower layers to the upper
layers through down-sampling and lateral linking. Such an improved feature pyramid has both semantic and
location information, which solves the problem as mentioned above.
In addition, YOLOv4 uses Mosaic and Self-Adversarial Training (SAT) for data enhancement. The principle
of Mosaic is to combine four training images into one for training, which can enrich the background and
enhance target detection in complex backgrounds. SAT is a novel data enhancement technique that is divided
into two phases. In the first stage, the neural network performs adversarial training by changing the original
image without changing the network weights. In the second stage, the neural network is trained to perform
standard target detection on the modified image. After the above data enhancement process, the robustness
of the model is improved.
Although YOLOv4 has a potent capability, we still want to improve its performance of detection speed and