
Page 86 - Read Online
P. 86
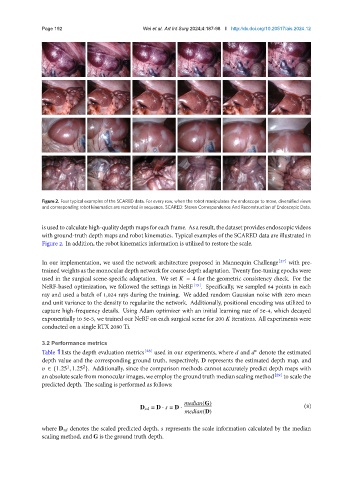
Page 192 Wei et al. Art Int Surg 2024;4:187-98 I http://dx.doi.org/10.20517/ais.2024.12
Figure 2. Four typical examples of the SCARED data. For every row, when the robot manipulates the endoscope to move, diversified views
and corresponding robot kinematics are recorded in sequence. SCARED: Stereo Correspondence And Reconstruction of Endoscopic Data.
is used to calculate high-quality depth maps for each frame. As a result, the dataset provides endoscopic videos
with ground-truth depth maps and robot kinematics. Typical examples of the SCARED data are illustrated in
Figure 2. In addition, the robot kinematics information is utilized to restore the scale.
In our implementation, we used the network architecture proposed in Mannequin Challenge [27] with pre-
trained weights as the monocular depth network for coarse depth adaptation. Twenty fine-tuning epochs were
used in the surgical scene-specific adaptation. We set = 4 for the geometric consistency check. For the
NeRF-based optimization, we followed the settings in NeRF [15] . Specifically, we sampled 64 points in each
ray and used a batch of 1,024 rays during the training. We added random Gaussian noise with zero mean
and unit variance to the density to regularize the network. Additionally, positional encoding was utilized to
capture high-frequency details. Using Adam optimizer with an initial learning rate of 5e-4, which decayed
exponentially to 5e-5, we trained our NeRF on each surgical scene for 200 iterations. All experiments were
conducted on a single RTX 2080 Ti.
3.2 Performance metrics
Table 1 lists the depth evaluation metrics [28] used in our experiments, where and denote the estimated
∗
depth value and the corresponding ground truth, respectively, D represents the estimated depth map, and
∈ {1.25 , 1.25 }. Additionally, since the comparison methods cannot accurately predict depth maps with
1
2
an absolute scale from monocular images, we employ the ground truth median scaling method [29] to scale the
predicted depth. The scaling is performed as follows:
median(G) (8)
D = D · = D ·
median(D)
where D denotes the scaled predicted depth, represents the scale information calculated by the median
scaling method, and G is the ground truth depth.