
Page 30 - Read Online
P. 30
Page 25 Qi et al. Intell Robot 2021;1(1):18-57 I http://dx.doi.org/10.20517/ir.2021.02
Features
Training Data
Different Features Different Features
Overlapping Labels
Sample IDs
Labels
Dataset A
Vertical Federated Learning
Dataset B
Features
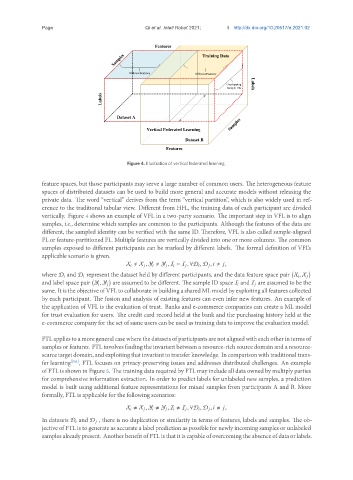
Figure 4. Illustration of vertical federated learning.
feature spaces, but those participants may serve a large number of common users. The heterogeneous feature
spaces of distributed datasets can be used to build more general and accurate models without releasing the
private data. The word “vertical” derives from the term “vertical partition”, which is also widely used in ref-
erence to the traditional tabular view. Different from HFL, the training data of each participant are divided
vertically. Figure 4 shows an example of VFL in a two-party scenario. The important step in VFL is to align
samples, i.e., determine which samples are common to the participants. Although the features of the data are
different, the sampled identity can be verified with the same ID. Therefore, VFL is also called sample-aligned
FL or feature-partitioned FL. Multiple features are vertically divided into one or more columns. The common
samples exposed to different participants can be marked by different labels. The formal definition of VFL’s
applicable scenario is given.
X ≠ X , Y ≠ Y , I = I , ∀D , D , ≠ ,
( )
where D and D represent the dataset held by different participants, and the data feature space pair X , X
(
)
and label space pair Y , Y are assumed to be different. The sample ID space I and I are assumed to be the
same. It is theobjectiveofVFL tocollaboratein buildinga shared ML modelbyexploiting all features collected
by each participant. The fusion and analysis of existing features can even infer new features. An example of
the application of VFL is the evaluation of trust. Banks and e-commerce companies can create a ML model
for trust evaluation for users. The credit card record held at the bank and the purchasing history held at the
e-commerce company for the set of same users can be used as training data to improve the evaluation model.
FTLappliestoamoregeneralcasewherethedatasetsofparticipantsarenotalignedwitheachotherintermsof
samples or features. FTL involves finding the invariant between a resource-rich source domain and a resource-
scarcetargetdomain, andexploitingthatinvarianttotransferknowledge. Incomparisonwithtraditionaltrans-
fer learning [16] , FTL focuses on privacy-preserving issues and addresses distributed challenges. An example
of FTL is shown in Figure 5. The training data required by FTL may include all data owned by multiply parties
for comprehensive information extraction. In order to predict labels for unlabeled new samples, a prediction
model is built using additional feature representations for mixed samples from participants A and B. More
formally, FTL is applicable for the following scenarios:
X ≠ X , Y ≠ Y , I ≠ I , ∀D , D , ≠ ,
In datasets D and D , there is no duplication or similarity in terms of features, labels and samples. The ob-
jective of FTL is to generate as accurate a label prediction as possible for newly incoming samples or unlabeled
samples already present. Another benefit of FTL is that it is capable of overcoming the absence of data or labels.