
Page 137 - Read Online
P. 137
Page 162 Boin et al. Intell Robot 2022;2(2):14567 I http://dx.doi.org/10.20517/ir.2022.11
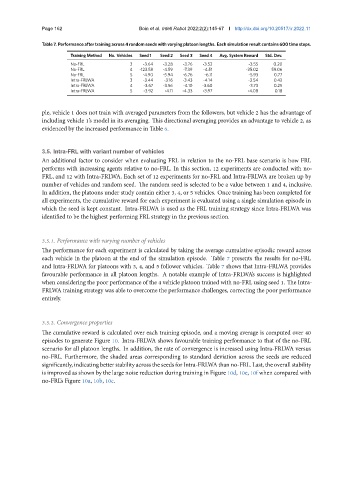
Table 7. Performance after training across 4 random seeds with varying platoon lengths. Each simulation result contains 600 time steps.
Training Method No. Vehicles Seed 1 Seed 2 Seed 3 Seed 4 Avg. System Reward Std. Dev.
No-FRL 3 -3.64 -3.28 -3.76 -3.52 -3.55 0.20
No-FRL 4 -123.58 -4.59 -7.39 -4.51 -35.02 59.06
No-FRL 5 -4.90 -5.94 -6.76 -6.11 -5.93 0.77
Intra-FRLWA 3 -3.44 -3.16 -3.43 -4.14 -3.54 0.42
Intra-FRLWA 4 -3.67 -3.56 -4.10 -3.60 -3.73 0.25
Intra-FRLWA 5 -3.92 -4.11 -4.33 -3.97 -4.08 0.18
ple, vehicle 1 does not train with averaged parameters from the followers, but vehicle 2 has the advantage of
including vehicle 1’s model in its averaging. This directional averaging provides an advantage to vehicle 2, as
evidenced by the increased performance in Table 6.
3.5. IntraFRL with variant number of vehicles
An additional factor to consider when evaluating FRL in relation to the no-FRL base scenario is how FRL
performs with increasing agents relative to no-FRL. In this section, 12 experiments are conducted with no-
FRL, and 12 with Intra-FRLWA. Each set of 12 experiments for no-FRL and Intra-FRLWA are broken up by
number of vehicles and random seed. The random seed is selected to be a value between 1 and 4, inclusive.
In addition, the platoons under study contain either 3, 4, or 5 vehicles. Once training has been completed for
all experiments, the cumulative reward for each experiment is evaluated using a single simulation episode in
which the seed is kept constant. Intra-FRLWA is used as the FRL training strategy since Intra-FRLWA was
identified to be the highest performing FRL strategy in the previous section.
3.5.1. Performance with varying number of vehicles
The performance for each experiment is calculated by taking the average cumulative episodic reward across
each vehicle in the platoon at the end of the simulation episode. Table 7 presents the results for no-FRL
and Intra-FRLWA for platoons with 3, 4, and 5 follower vehicles. Table 7 shows that Intra-FRLWA provides
favourable performance in all platoon lengths. A notable example of Intra-FRLWA’s success is highlighted
when considering the poor performance of the 4 vehicle platoon trained with no-FRL using seed 1. The Intra-
FRLWA training strategy was able to overcome the performance challenges, correcting the poor performance
entirely.
3.5.2. Convergence properties
The cumulative reward is calculated over each training episode, and a moving average is computed over 40
episodes to generate Figure 10. Intra-FRLWA shows favourable training performance to that of the no-FRL
scenario for all platoon lengths. In addition, the rate of convergence is increased using Intra-FRLWA versus
no-FRL. Furthermore, the shaded areas corresponding to standard deviation across the seeds are reduced
significantly,indicatingbetterstabilityacrosstheseedsforIntra-FRLWAthanno-FRL.Last, theoverallstability
is improved as shown by the large noise reduction during training in Figure 10d, 10e, 10f when compared with
no-FRL’s Figure 10a, 10b, 10c.