
Page 85 - Read Online
P. 85
Page 278 Zhang et al. Intell Robot 2022;2(3):27597 I http://dx.doi.org/10.20517/ir.2022.20
Training in simulation Policy Real machine
Reward deployment
Simulation environment
Policy
State
Action
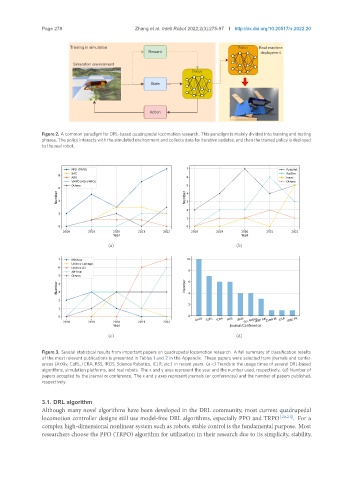
Figure 2. A common paradigm for DRL-based quadrupedal locomotion research. This paradigm is mainly divided into training and testing
phases. The policy interacts with the simulated environment and collects data for iterative updates, and then the trained policy is deployed
to the real robot.
7
PPO (TRPO) Pybullet
SAC RaiSim
8
6
ARS Isaac
VMPO (MO-VMPO) Others
5
Others
6
Number 4 Number 4 3
2
2
1
0 0
2018 2019 2020 2021 2022 2018 2019 2020 2021 2022
Year Year
(a) (b)
10
7
Minitaur
Unitree Laikago
6 Unitree A1
8
ANYmal
5 Others
Number 4 3 Number 6 4
2
2
1
0
0
ArXiv CoRL ICR A RSS IROS obot. IEEE R AL CVPR W . ICLR IEEE TR
Sci. R
2018 2019 2020 2021 2022
Year Journal/Conference
(c) (d)
Figure 3. Several statistical results from important papers on quadrupedal locomotion research. A full summary of classification results
of the most relevant publications is presented in Tables 1 and 2 in the Appendix. These papers were selected from journals and confer-
ences (ArXiv, CoRL, ICRA, RSS, IROS, Science Robotics, ICLR, etc.) in recent years. (a-c) Trends in the usage times of several DRL-based
algorithms, simulation platforms, and real robots. The x and y axes represent the year and the number used, respectively. (d) Number of
papers accepted by the journal or conference. The x and y axes represent journals (or conferences) and the number of papers published,
respectively.
3.1. DRL algorithm
Although many novel algorithms have been developed in the DRL community, most current quadrupedal
locomotion controller designs still use model-free DRL algorithms, especially PPO and TRPO [20,21] . For a
complex high-dimensional nonlinear system such as robots, stable control is the fundamental purpose. Most
researchers choose the PPO (TRPO) algorithm for utilization in their research due to its simplicity, stability,