
Page 37 - Read Online
P. 37
Qi et al. Intell Robot 2021;1(1):18-57 I http://dx.doi.org/10.20517/ir.2021.02 Page 32
Observed
Agent A
Environment A
Environment A
Local Model A Local Model B Environment B Agent B State Action Agent A Reward State
Environment C
Local Model C
Observed
Reward
Action
s t+1
Local Model X Agent C Action Reward State Vertical Global Environment Agent N Environment B
Environment N
Agent B
r t+1
Train
s t
a t
r t
Agent N Observed Environment N
Horizontal Federated Reinforcement Learning Vertical Federated Reinforcement Learning
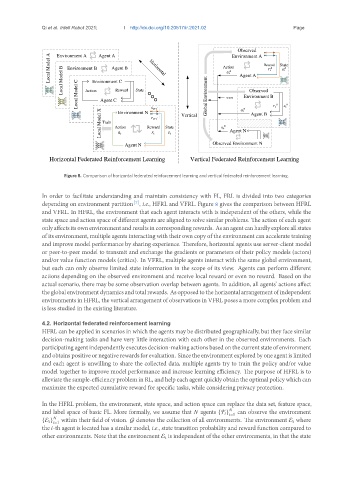
Figure 8. Comparison of horizontal federated reinforcement learning and vertical federated reinforcement learning.
In order to facilitate understanding and maintain consistency with FL, FRL is divided into two categories
[7]
depending on environment partition , i.e., HFRL and VFRL. Figure 8 gives the comparison between HFRL
and VFRL. In HFRL, the environment that each agent interacts with is independent of the others, while the
state space and action space of different agents are aligned to solve similar problems. The action of each agent
onlyaffectsitsownenvironmentandresultsincorrespondingrewards. Asanagentcanhardlyexploreallstates
of its environment, multiple agents interacting with their own copy of the environment can accelerate training
and improve model performance by sharing experience. Therefore, horizontal agents use server-client model
or peer-to-peer model to transmit and exchange the gradients or parameters of their policy models (actors)
and/or value function models (critics). In VFRL, multiple agents interact with the same global environment,
but each can only observe limited state information in the scope of its view. Agents can perform different
actions depending on the observed environment and receive local reward or even no reward. Based on the
actual scenario, there may be some observation overlap between agents. In addition, all agents’ actions affect
theglobalenvironmentdynamicsandtotalrewards. Asopposedtothehorizontalarrangementofindependent
environments in HFRL, the vertical arrangement of observations in VFRL poses a more complex problem and
is less studied in the existing literature.
4.2. Horizontal federated reinforcement learning
HFRL can be applied in scenarios in which the agents may be distributed geographically, but they face similar
decision-making tasks and have very little interaction with each other in the observed environments. Each
participating agent independently executes decision-making actions based on the current state of environment
andobtainspositiveornegativerewardsforevaluation. Sincetheenvironmentexplored byoneagentis limited
and each agent is unwilling to share the collected data, multiple agents try to train the policy and/or value
model together to improve model performance and increase learning efficiency. The purpose of HFRL is to
alleviate the sample-efficiency problem in RL, and help each agent quickly obtain the optimal policy which can
maximize the expected cumulative reward for specific tasks, while considering privacy protection.
In the HFRL problem, the environment, state space, and action space can replace the data set, feature space,
and label space of basic FL. More formally, we assume that agents {F } =1 can observe the environment
{E } within their field of vision. G denotes the collection of all environments. The environment E where
=1
the -th agent is located has a similar model, i.e., state transition probability and reward function compared to
other environments. Note that the environment E is independent of the other environments, in that the state